2025年、LLFarMではLLMを用いて、高精度で pdf 由来のドキュメントから高精度に文字情報、画像情報、その他を検出することに成功しました。
LFarM:画像処理×LLMで、PDFから“意味”を高精度に抽出
LLFarMは、LLMを用いた業務システム開発ブランドです。
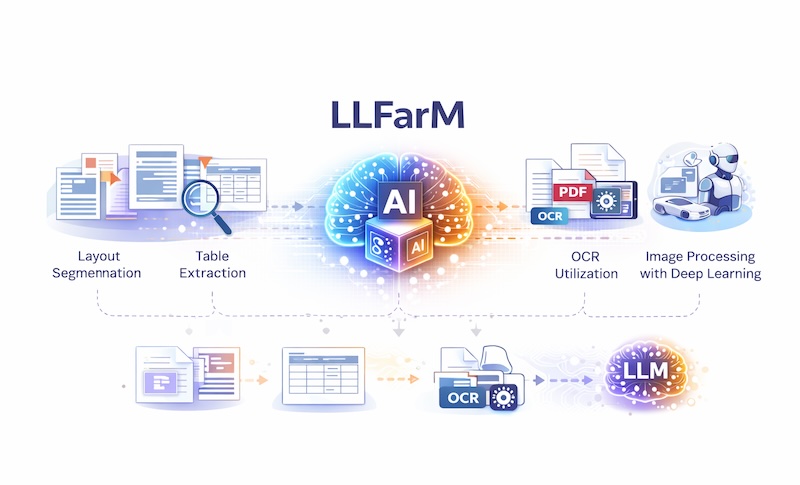
今回の成果は、長年Deep Learning / Computer Visionで培ってきた画像処理技術を“前処理”として組み込むことで、PDFドキュメントから意味情報を高精度に抽出できた点にあります。
一般的なOCRは、文章(テキスト)を高精度に検出できます。一方で、図・表(Table)・レイアウト構造を含むドキュメントでは、読み取り結果が「崩れる」「要素が混ざる」「セル結合や列の対応が乱れる」といった課題が残りやすく、LLMに渡しても意図した理解に繋がらないケースがあります。
LLFarMでは、PDFを単に文字起こしするのではなく、ドキュメントを“理解可能な構造”に再構成してからLLMへ入力します。これにより、図表を含む資料でも、検索・要約・QA・RAGで利用できる品質まで引き上げました。